
Table of Contents
Back in 2013, the head of search spam at Google, Matt Cutts, estimated that at least a quarter of all internet content was duplicated. Despite its prevalence, marketers still worry about its effect on their SEO.
While content duplication is something that you generally want to avoid in your own content, it won’t always hurt your rankings on search engine results pages (SERPs). Before you panic about having duplicate content, it’s helpful to understand exactly what it is and how it impacts your SEO performance.
What is duplicate content?
Duplicate content is identical or nearly identical content found in multiple locations across the web. Examples of duplication include product descriptions, data policies, and other business materials that don’t change throughout a website. While much of this duplication is unintentional, it’s not always. Some marketers steal others’ work and post it on their own sites to take the shortcut to more traffic.
Duplicate content is not the same as two pages covering the same topic. Two creators may write separate articles on living room decor, but the overlap they’re likely to have doesn’t mean they’re necessarily duplicates.
In rare cases, duplicate content issues are the result of plagiarism, where someone outright steals and posts your work without giving you credit. The majority of content duplication, though, comes from technical site issues or content scraping.
When search engine crawlers come across duplicate content, they get confused. They have to work harder to figure out which version to index, rank, and pass link equity to. And these effects extend to marketers as well.
Any duplicated pages will most likely have lower SEO rankings in search results unless you’ve designated a canonical URL. Without a canonical link, crawlers get confused about where to send link equity. This causes them to either spread it among any duplicate pages or direct all of the equity to just the page they decide to index. In either case, the content becomes less effective for your site’s overall SEO performance.
Why duplicate content is bad for webmasters and Google
Content duplication might not always have a direct impact on your SEO, but it still affects your site’s performance. There are multiple reasons why you want to avoid duplicate content from an SEO perspective:
- Higher-ranking scraped content: Many factors determine a page’s rankings. If a scraped piece of content has better optimization in other areas, it can potentially rank higher than your original content.
- URL appeal: When there are different versions of a URL in Google’s index, any one of them can end up in search results. If a complicated, unattractive URL makes its way onto the SERPs, it might generate less organic traffic than the SEO-friendly URL would have. That’s because it may appear spammy to users.
- Weakened link equity: Duplicate pages can “steal” backlinks from the original version. This passes some of the link equity to areas where it might not have gone otherwise.
- Lower potential rankings: Google can’t always recognize which version of a page is the one that should rank. Without a canonical tag, duplicate pages may end up on SERPs while the original URL suffers in the rankings.
The good news is that there are many well-known causes of these issues. And you can solve most of them with some technical SEO fixes.
Common causes of duplicate content
The main reason why Google doesn’t automatically penalize duplicate content is because it can happen for many reasons. Several are totally innocent. These are some of the most common causes and sources of duplication that you should be aware of while creating content.
Faceted navigation
Ecommerce sites typically run into duplication issues when they implement a faceted navigation search feature on category pages and product pages. This allows users to filter and sort for specific product options.
Content duplication issues when the same faceted search creates similar web pages. Because of its customizability, faceted navigation can create several web pages that lead to the same results.
For example, imagine that two different users are shopping for a gray shirt on ThredUp. Both start by filtering out for the color gray:
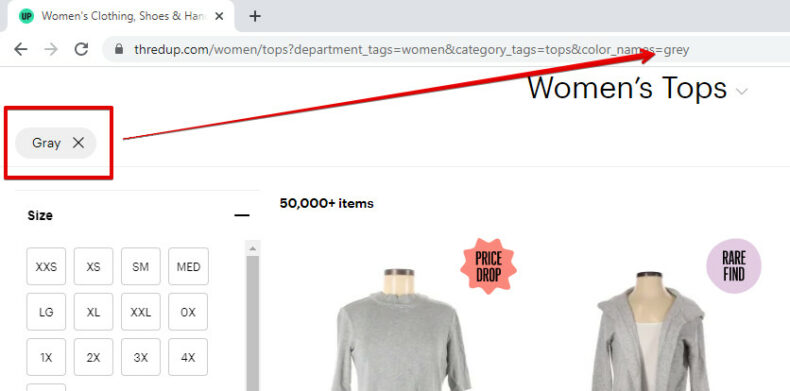
From there, however, the users take a different series of steps.
User 1 first filters for short sleeve shirts and then cotton shirts:

User 2 starts by filtering for cotton shirts and then looks for only short sleeve ones:

This results in the exact same content at two different web addresses. The duplicate content can add up quickly when users have the ability to filter out certain characteristics.
Case sensitive URLs
Consistent URL structure is an important SEO best practice that you should always follow. This includes capitalization within URLs. Google treats web addresses as case-sensitive, meaning that you need to pick a format and stick with it.
If you use all lower-case, stick with all lower-case:
yourwebsite.com/blog
yourwebsite.com/about-us
If you choose to capitalize URLs, make sure they all follow that style:
yourwebsite.com/BLOG
yourwebsite.com/ABOUT-US
When you mix and match, you can create multiple web addresses for the same content, leading to duplication problems. These different URLs represent unique locations but most likely have identical content:
yourwebsite.com/blog
yourwebsite.com/BLOG
Clearly define your URL format so that all of your pages are uniform and unlikely to be duplicated in the future.
Tracking parameters
Adding tracking parameters to your URLs is a great way to monitor a campaign’s success. The additional parameters create extra versions of the same content.
There are many ways to prevent URL parameters from causing duplication issues. You can add canonical tags or noindex tags to duplicate pages or put a disallow directive in your robots.txt file for any future pages. It’s also possible to manage parameters in Google Search Console.
User session IDs can cause a similar problem, and you can solve it with basic canonicalization.
HTTP vs. HTTPS
You need to make sure that your site only uses HTTP or the HTTPS protocol. Otherwise, the Google Panda algorithm will treat them as duplicate pages.
Prevent this issue using the Yoast SEO plugin, which allows you to adjust canonical settings:
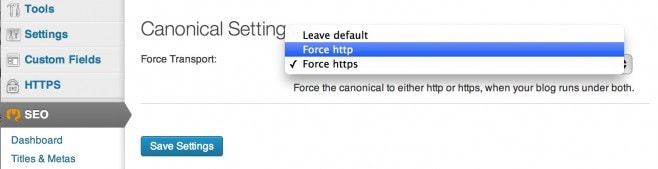
You can also add a meta robots tag or update your robots.txt file if the plugin isn’t an option.
WWW vs. Non WWW
Search engines also treat pages separately if one uses “www” in the subdomain and the other does not. To stop them from competing in SERPs, use a redirect to ensure users can only access one version.
Google Webmaster Tools allows you to select a preference, but you have to own both domain names. This may be a good option if you have a large website and a big audience.
Trailing slashes and non-trailing slashes
When you add a trailing slash to the end of a URL, you create an entirely new URL. Consider these URLs:
yourwebsite.com/blog/
yourwebsite.com/blog
Google will treat them as separate pages. You want to make sure that users can only access one of these locations. Most sites will redirect users to the accessible page to avoid duplicate content problems. You can do this with a WordPress plugin or manually through your HTML code.
Localization
Creating global SEO content is a great way to reach a wider audience. If you create URLs for multiple countries that speak the same language, however, the near-identical pages may compete in search rankings.
If you add a hreflang tag to your pages, Google will understand who they are targeted for.
<link rel=”alternate” hreflang=”lang_code” href=”url_of_page” />
This will prevent confusion and allow each targeted web page to serve its target market without hurting the other versions.
Paginated comments
Your content management system (CMS) may create paginated comments on your site. These extra pages then become duplicate content URLs that may hurt the overall SEO performance of the content. Luckily, there are likely settings within your CMS that can help you manage paginated comments easily.
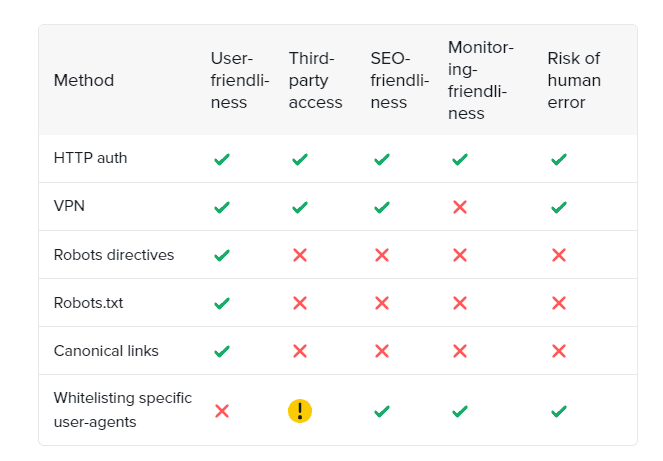
Staging environment
A staging environment where you test new website features can accidentally cause duplicate content issues. To prevent Google or Bing from indexing your staging site, there are several methods you can use, like robots directives, canonicalization, and more of what you see in the following infographic:
Is there a duplicate content penalty?
There is no official penalty for duplicate content, but websites may suffer consequences regardless. As Susan Moskwa, a former Webmaster Trends Analyst at Google pointed out back in 2008, scraped content is against Google’s Webmaster Guidelines. Because duplicate content issues occur for many reasons, they won’t necessarily cost you.
The search engine looks for the intent behind similar content. Sometimes, a website may have duplicate pages of its original content. Other times, creators may try to paraphrase others’ work but land too close to the original. And in certain cases, marketers blatantly steal content from other brands.
Google determines intention by looking for clues like doorway pages and affiliate program pages. If you are found guilty of intentionally producing duplicate content, you may be notified of a guidelines violation requiring a manual action review.
How much duplicate content is acceptable?
There is no set limit for how much duplicate content you can have. If you publish duplicate content, make sure to use a canonical tag, so Google knows which version to index.
Other than that, it’s okay to have some overlap across pages in the form of legal policies and other boilerplate content. Having some repetitive information throughout the site won’t impact your rankings.
As far as scraped content goes, search engines are highly capable of discerning the original from the duplicate. Sometimes, the copied content does end up ranking higher than your own version. So, it’s a good practice to check for duplicate content every now and then.
How to check for duplicate content
Finding duplicate content is relatively easy. One of the simplest ways to do so is through the search engine. All you have to do is copy a portion of your text into the search bar and view the results.
If your website comes up as the top post, Google recognizes it as the original source of that content. If you see other sites with the same text (and especially in the top spot), you may need to investigate further to see whether they’ve stolen your content.
If you plan to do this frequently, however, using a content checker is the best option. Here are some tools that you can use to verify that you’re publishing unique content and to find others who have scraped your own:

Using these tools can prevent you from unintentionally publishing scraped content. They will show you the parallels between what you’ve created and some of the sources you may have used to research and brainstorm. This simple process can save you the hassle of a penalty down the line.
Best practices for avoiding duplicate content
Search engines do their best to discern whether the content is purposefully duplicated or not. In the case that it suspects malicious intent, your web pages will likely suffer in search rankings. These are some of Google’s best practices for eliminating duplicate content from your website.
Learn about your content management system
Every CMS displays web pages differently. When you create a new page or post, your CMS can create a duplicate to store in the site’s archives.
It may also feature the content on your site’s homepage, meaning that Googlebot will see the same information in multiple locations. Learn about how your CMS stores and displays content so that you can proactively prevent duplication issues.
Reduce boilerplate redundancy
Boilerplate content is something that you publish for widespread use either across your website or in media publications. Because this text doesn’t frequently change (if at all), it can cause duplicate content issues. Rather than posting your entire boilerplate paragraph, condense it into a smaller version and link out to the full version.
Google’s Parameter Handling tool can help you block the crawling of this content. To use it, you must have more than 1,000 pages on your site, and there must be indexed duplicate content separated only by URL parameters.
Add consistent internal links
When you add internal links to your page, stick with the same URL format. For example, say that you use this format for several links:
http://www.example.com/blog
You’ll want to continue using that structure for the rest of your internal links to that page.
Implement 310 redirects
Any time that you change your website architecture, you need to use 301 redirects. You should also use them when you overhaul a piece of content, switch domains, condense multiple pages into one, or change your URL. These ensure that any link equity from the original page is passed to the new one.
Properly syndicate your content
Content syndication is an effective way to get your web pages in front of a large audience. The only problem is that when you publish the same content across multiple sites, Google will usually only display one version on SERPs. This version may not be your original one.

Make sure that when you upload the post to other sites/locations, you include a link to the original version. Not only can this increase your site traffic, but it also signals to Google where the post came from originally.
Google recommends asking external publishers to add a nofollow tag to the page so that it doesn’t get crawled and indexed for their site, potentially disrupting your own page’s rankings.
Hide or eliminate stubs
Stubs are web pages that haven’t been finished yet. When you publish these before they’re done, you can negatively impact your rankings.
As a rule of thumb, try to draft your content separate from your CMS. Once you have the outline or rough draft completed, add the content to a new blog post or web page.
This may prevent you from having low-quality web content crawled and indexed. When you create a stub as a placeholder for future content, make sure to add a noindex tag so that Google won’t crawl it.
Consolidate similar web pages
It is common for marketers to end up with several different pages on the same topic. Depending on the target keyword and audience, these pages may have significant overlap.
If so, you can consolidate the separate pages into one larger resource that reduces the amount of crossover. The newly-formed content may rank even higher for the target keyword, given that it probably covers the topic more in-depth.
Use top-level domains
When creating international SEO content, use top-level domains to specify where in the world the page should rank. An example domain name would be:
This tells the search engine that the content is targeted at users in Spain. This separates similar web pages for different regions and reduces the chance that they cannibalize each others’ rankings in search results. It also improves user experience, giving users in different countries more relevant information.
Get a complimentary SEO audit
Google does not have an official penalty for duplicate content problems. Regardless, you want to avoid these issues where you can since they can negatively impact your SEO rankings. Make regular SEO audits part of your digital marketing strategy to prevent duplicate content issues.
Want to see how you’re doing with SEO? Get an instant SEO audit below. Or, schedule a free consultation to see how intent SEO can boost search traffic revenue by 700%.